MSPC: The Hub:
The hub is built as a PanGeo Cloud environment in a JupyterHub instance. Let’s take that apart, working backward:
According to the PanGeo Cloud docs, JupyterHub “JupyterHub brings the power of notebooks to groups of users. It gives users access to computational environments and resources without burdening the users with installation and maintenance tasks. Users - including students, researchers, and data scientists - can get their work done in their own workspaces on shared resources which can be managed efficiently by system administrators.”
PanGeo is a community of folks who develop and provide compute tools and a cloud-based compute workflow and environment for big-data geocomputing. This approach to geocomputing depends on a set of core packages that are also central to MSPC workflows (mostly, though I haven’t found myself needing to use Iris in my own work so far), and thus are very worth taking the time to learn well. (Note: Their documentation is excellent and, unlike most cloud computing documentation, it is built with scientists in mind rather than private industry! I recommend starting with their
The PanGeo Cloud is a cloud-basd data-science environment
in which each user has a private, virtual environment (analogous to a user space on a bare-metal server like a campus supercomputer), called /home/jovyan, which is intended only for code, notes, small data, etc. (10 GB limit).
The compute environment is accessed through the browser, so you just log in there,
and you can up/download smaller objects/files directly to the home directory
(though you should defer to using Git/GitHub as much as possible).
Data of any ‘meaningful’ size should not be stored in Azure cloud storage instead. (Note: for MSPC work, they must be stored in the westeurope Azure region, so that are colocated with the MPSC servers.)
Data should be stored in cloud-optimized formats (e.g., Cloud Optimized Geotiffs (COGs)) and then indexed using a SpatioTemporal Asset Catalogs (STAC) so that their contents can be easily searched (along spatiotemporal dimensions as well as on the basis of other metadata, e.g., cloud fractions) and then streamed into analyses. (For more on STAC, see the details on the STAC page.)
(FYI: Cloud storage is effectively a key-value system, where keys are strings and values are bytes of data. Data is read and written using HTTP calls. Importantly, performance of object storage is very different from file storage; according to the PanGeo docs: “On one hand, each individual read / write to object storage has a high overhead (10-100 ms), since it has to go over the network. On the other hand, object storage “scales out” nearly infinitely, meaning that we can make hundreds, thousands, or millions of concurrent reads / writes. This makes object storage well suited for distributed data analytics. However, the software architecture of a data analysis system must be adapted to take advantage of these properties. All large datasets (> 1 GB) in Pangeo Cloud should be stored in Cloud Object Storage.”
Interactive Jobs
The following will walk you stepwise through an interactive session in the Hub (with images):
-
Navigate to the MSPC homepage.
-
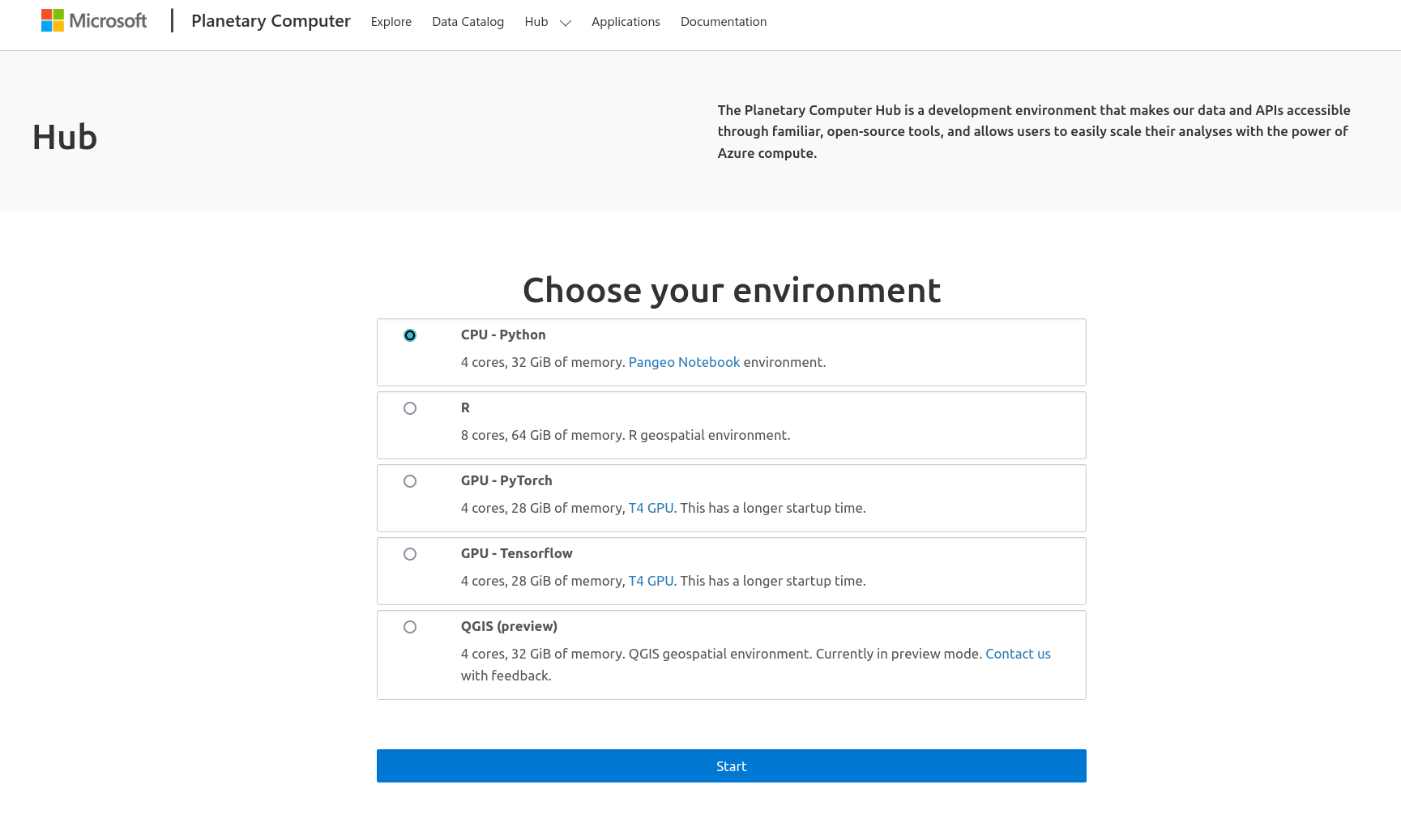
Click on the ‘Hub’ tab at top, choose the notebook server environment you wish to work in, then click the blue ‘Start’ button. (Note: the ‘CPU - Python’ option will use the Pangeo Notebook environment discussed above)
-
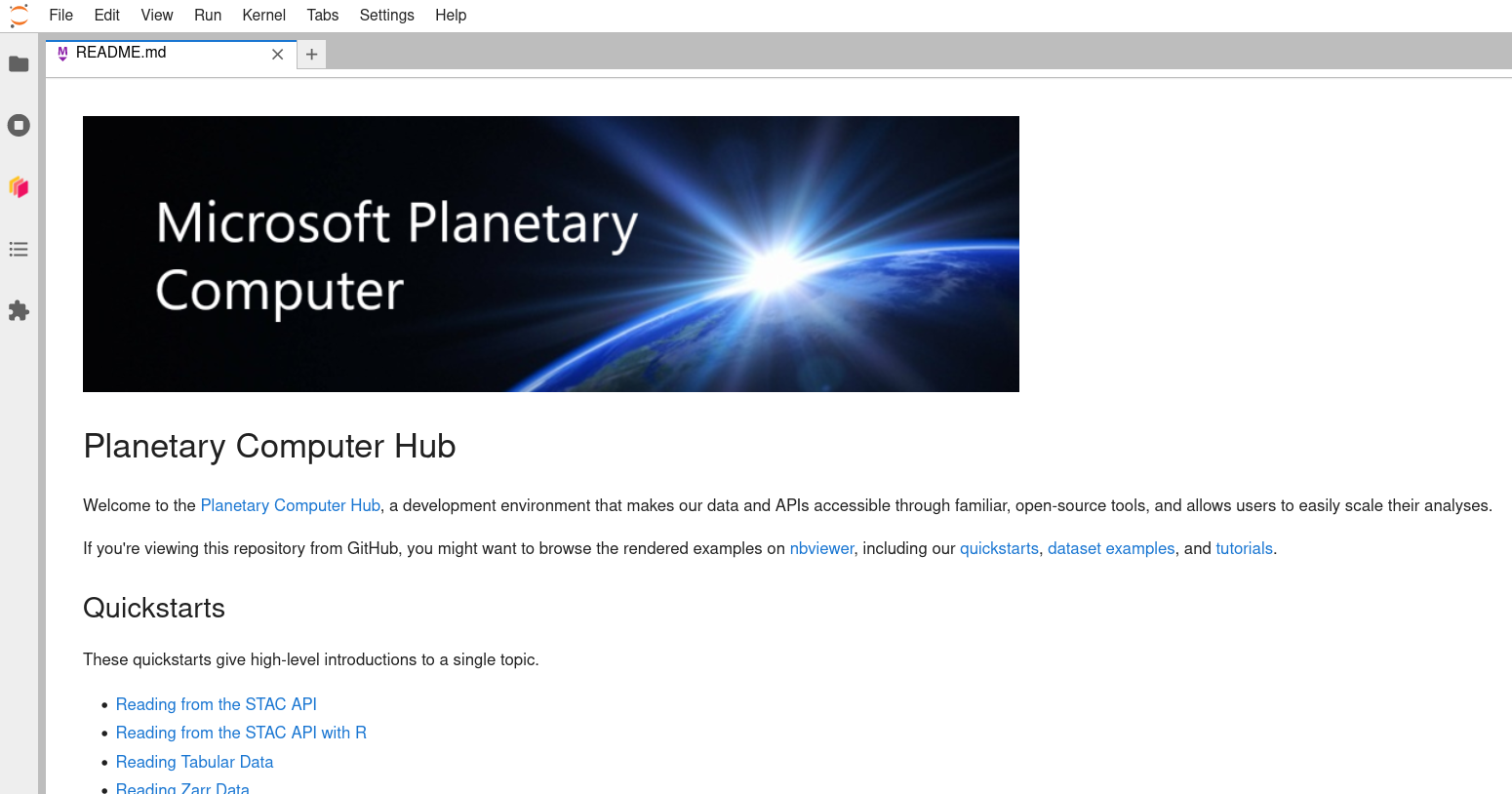
After some amount of time, your server will start up and you will be redirected to the a Jupyterhub instance with a landing-page README that you can use to practice/learn more.
-
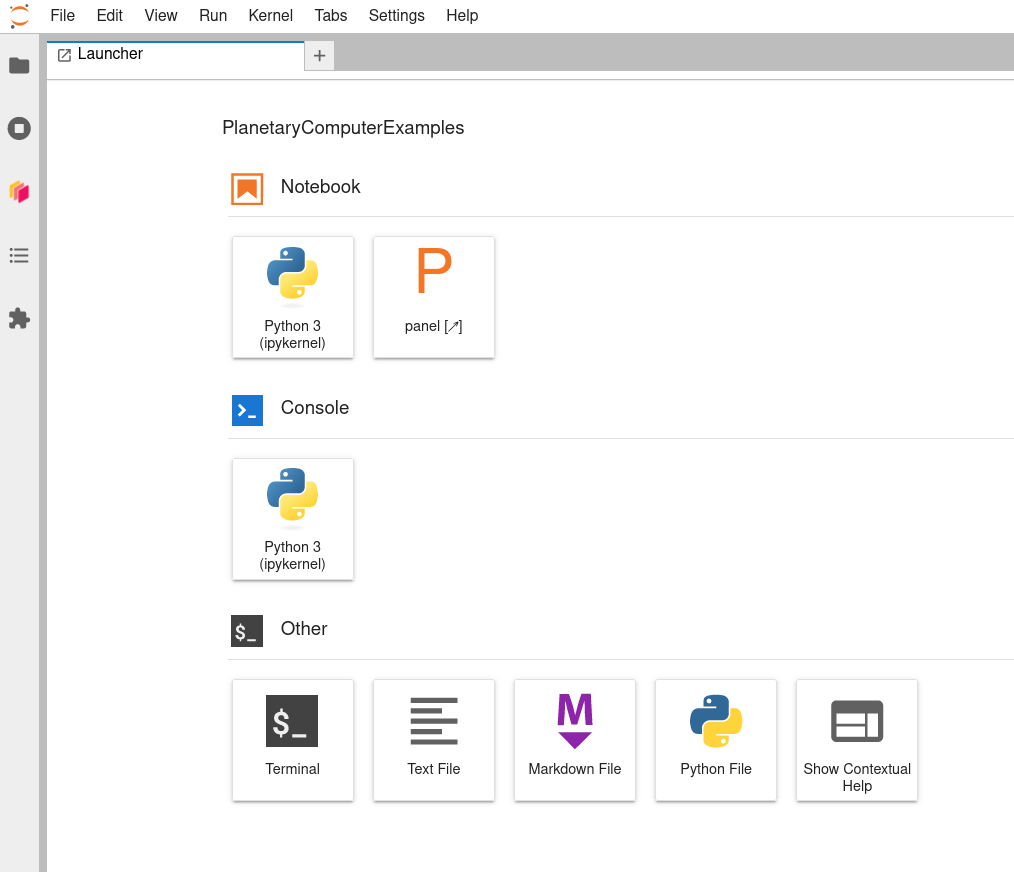
After closing that README tab, you should see a Launcher tab with a number of notebook, console, and other options.
-
Before you start working in a notebook by clicking on a notebook logo within the Launcher, you may want to be sure you choose a working directory to work in. Use your mouse (or
-B) to open the bookmark tab at the left.  -
Navigate ‘upward’ through the directory tree by clicking on the parent directory’s folder icon to the left of the current working directory’s name (which should be “PlanetaryComputerExamples”). This will put you in your home directory on the Hub. Then click the new directory icon above (folder with a plus sign in it) and create and name a new directory (here, labeled ‘my_MSPC_work’).

-
Double-click on that new folder to navigate ‘downward’ into it, then launch a Python 3 (ipykernel) notebook using the Launcher tab’s icon.
-
You can now use the Jupyter notebook interface as you may have before (here is a good starting point if this interface is new to you) to rename your notebook, do some work, and save your work as you go. Working in this new subdirecotry/folder that you created for yourself (‘my_MSPC_work’ in the example above) will allow you to save your work in a way that it is not wiped between sessions, and thus is still available).
-
When finished working for now, don’t forget to save your work, close your notebook (a Launcher tab will reappear to take its place), and then click File -> Hub Control Panel to get to the controls for your running server.
-
When you arrive at the Hub Control Panel page, double-click ‘Stop My Server’ to stop it from running’
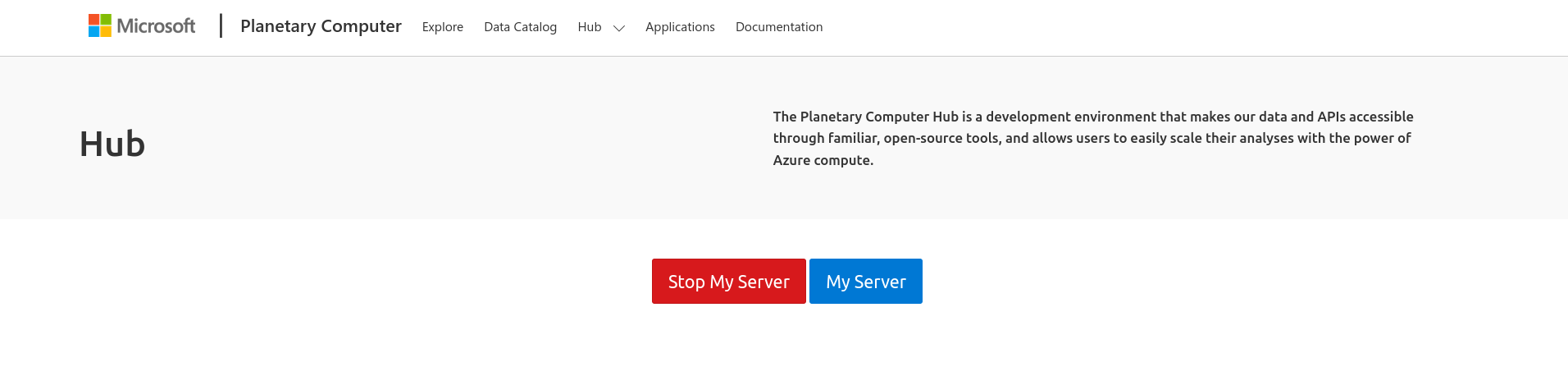
If you want to work with code that is version-controlled on GitHub (highly recommended!), then the following steps will get you set up:
-
In a new browser tab/window, visit the GitHub repository (or ‘repo’) that you want to clone (i.e., copy) the code of, click the green “<> Code” button, then click the copy icon next to the link that is displayed.

-
Back in the MSPC browser tab/window, use the Launcher tab to launch a bash terminal.

-
Call the bash
cd ~command (i.e., typecd ~into the terminal’s command line, then hitto execute it) to make sure you have navigated to your home directory. 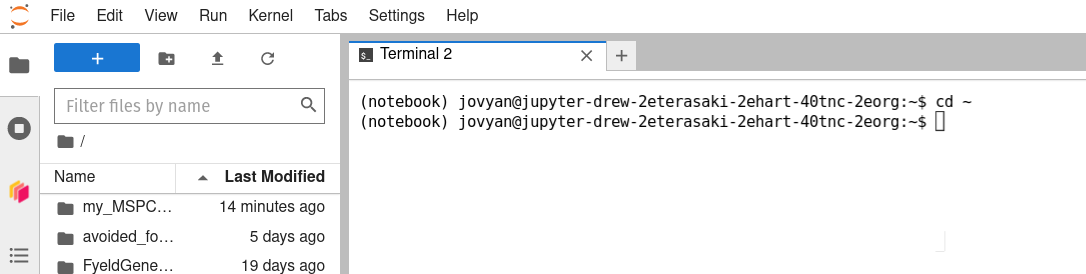 -
Type
git cloneinto the terminal, then use-V to paste the GitHub repo's URL into the command line, then hit . (Note: If you are attempting to clone a private GitHub repo to which you have access, you will be prompted to authenticate. Enter your username, press , then enter your password (type carefully; for security purposes, no characters appear when passwords are typed into the command line), and press again.) 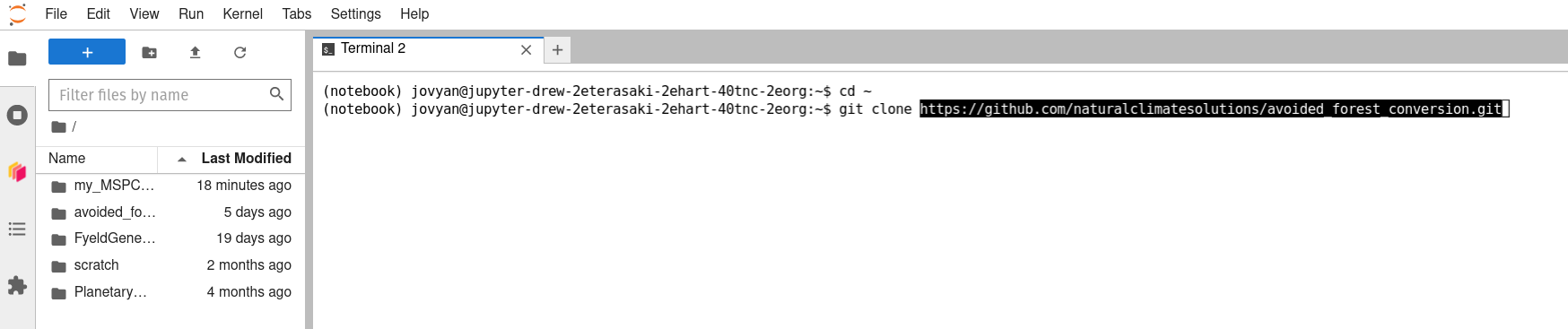 -
Once the command has finished running successfully (you will be returned to a new command line that is awaiting further input), you can click the terminal tab’s ‘x’ to close it (a new Launcher tab will reappear in its place again), navigate into the newly cloned directory using the bookmarks tab at the left, and double-click on any Jupyter Noteook files (.ipynb extensions) or other files you wish to edit to begin working with them on the Hub.
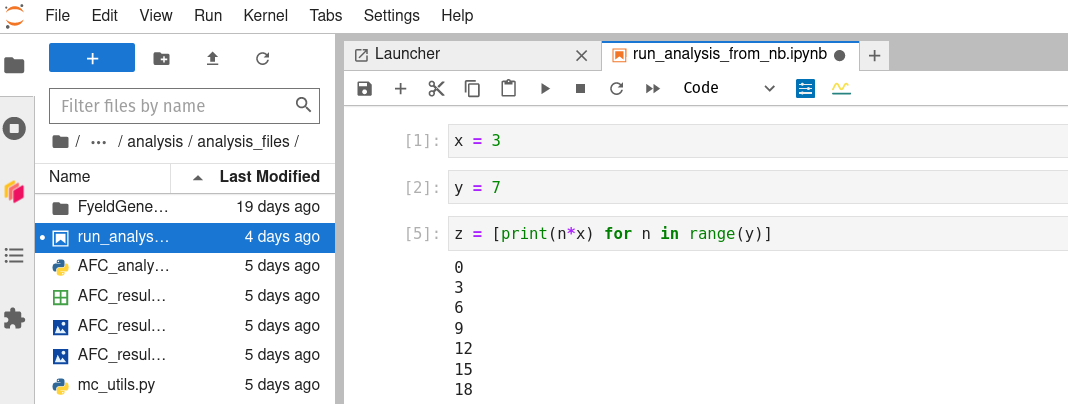
TODO: ADD INSTRUCTIONS FOR COMMITTING AND PUSHING CHANGES BACK TO GITHUB
Next steps:
Dask:
Dask is an important part of Pangeo Cloud, and thus of the MSPC Hub. It is used to parallelize large calculations: i.e., to break them into small pieces, run them all simultaneously on a ‘cluster’ of networked comuter nodes, or ‘workers’, and then to combined all the sub-results into a final overall result at the end, allowing for faster real-world, or ‘wall-clock’, runtimes than would be possible if the whole job were run by one single, large computer. This adds considerable to an overall compute task, so it is really not worth doing unless a standard, single-computer workflow is not well suited to your task. If that is the case (e.g., it will take a prohibitively long time to run), and if your job can be parallelized well (e.g., it can be thought of as doing identical and independent computations on subsets of your overall dataset, such as running simple raster algebra on raster tiles as a way of running the same computation on the very large composite raster), then Dask may be the key to achieving your goal. In that case, please see the dask page for more detail!
Batch Jobs with kbatch:
On a standard cluster, such as a campus supercomputer, the last step
in a workflow may often be to submit a full, scaled-up analysis
as a batch job (which may take many hours or days to run to completion).
On the MSPC Hub, you can follow a roughly similar workflow,
using the kbatch command to submit batch jobs.
For more details, see the kbatch page!
Bringing Your Own Data, and working with STAC:
There are plenty of quick example workflows provided in the ‘Example Notebook’ tabs under each of the datasets in the MSPC Data Catalog (e.g., GBIF), and they can be opened interactively, run, and messed with in the Hub by clicking the blue ‘Launch in Hub’ button in the page.
MSPC also provides a number of examples that are a bit longer and more detailed, and that demonstate some key workflows, in the ‘Quickstarts’ section of the documentation.
If those workflows mirror your workflow close enough to get you started, and if you want to work exclusively with data that is already in the MSPC Data Catalog, then you might be ready to jump in an start building an analysis!
However, if you want to work with data that is not already in the MSPC Data Catalog then you’ll need to do some manual interaction with Azure storage containers. Take a quick look at this blob-storage example to get a very basic glimpse of how that might look. Then move on to my notes on creating a STAC for your own data and using that data in MSPC for much more detail!